Another month, another roundup post. This month has been very… exercise-y. Which is, for the record, not normal for me. For the previous year my only source of exercise has basically been walking, but that’s not a great fitness activity for me. When my regular walks entered the 10-15km territory it got more and more annoying to find the time and/or an interesting route. I also managed to i...
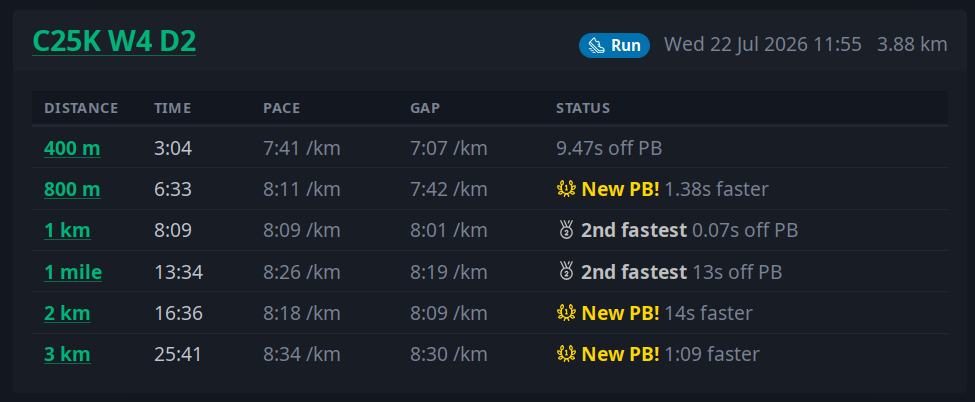
I’ve recently been bitten by some kind of strange exercise bug. I’ve gone from being mostly sedentary to struggling to not go out for a cheeky bike ride on a day that’s meant to be a rest day. Maybe this is what a midlife crisis feels like? Anyway, one of the things I’ve enjoyed about this development is seeing my personal best efforts gradually go up. There’s somethi...
Writing these monthly posts is making me very aware of how quickly the year is going. I’m not sure I like that at all. June saw some truly horrible hot weather in the UK; it’s almost like murdering the planet with CO₂ emissions was a terrible, terrible idea. My dodgy knee that I mentioned way back in the April post feels like it’s finally back to normal. I had low expectations ...