Generating infinite avatars
Published on

An example of one of the unique avatars
I recently added a new ‘about’ section to the top of my website. Like most about pages, it has a picture. Instead of a normal photograph, however, you’ll see an AI-generated avatar. This is admittedly fairly trendy at the minute — apps like Lensa offer to make you profile pictures if you give them a set of photos and some cash — but I’ve done something a bit different.
You see, there is not just one image that has been carefully curated, edited, and uploaded. No, the image you see quite possibly has never been seen before and will never be seen again. It’s unique. Just for you.
Background: Stable Diffusion, DreamBooth, et al
You’ve probably heard of Stable Diffusion, the open text-to-image model developed by LMU Munich. Given a text prompt it starts with a random array of static and repeatedly transforms it, each step moving away from pure entropy and towards a real image that befits the prompt1. It stands in contrast to competitors like DALL-E and Midjourney in both the code and the model being freely and publicly available.
One interesting side effect of that is that you can take the pre-trained Stable Diffusion model, and run your own further training on top. It takes hundreds of thousands of GPU hours to train such a model from scratch, but only a few to add some specific tweaks on top. Earlier this year researchers from Boston University and Google Research published a paper titled DreamBooth which presents a model for doing exactly that.
This research has spawned a slew of startups that do the training and/or generation for you in return for cold, hard cash. The most popular of these at present is Lensa, a mobile app that will generate 200 avatars for you in pre-set styles for £9.99. You can’t change the styles or regenerate any you don’t like, but from what I hear 200 is just about enough that you’ll find one or two that you like.
The lovely ASCII art shown while training is underway
While £9.99 isn’t much money, if you’re technically inclined then it’s not very difficult to do the work yourself for free. That also lets you come up with unique prompts, creating pictures in different styles, with different backgrounds, and so on. I used the wonderful notebooks from TheLastBen that run in Google Colab. The generous free tier offered by Colab is plenty enough to run a DreamBooth training session, and the notebook walks you through pretty much everything2.
If you train a custom model then you end up with a weighty file called a “checkpoint”, which you can provide to most Stable Diffusion tools to use when generating images. I use AUTOMATIC1111’s stable-diffusion-webui which not only offers a simple web UI, but also a REST API for accessing it programmatically. I installed this on my laptop and spent a happy hour or two generating weird and wonderful pictures of me.
Automating it
When I was training the model, I was planning on finding a single nice avatar to use. After playing around with it for a while, though, I wanted to expose all the wacky and unique pictures that it was generating. I came up with the rough idea of batch generating a number of avatars, then having a custom webserver that served you one and deleted it.
My first attempt at this was to try and run the Stable Diffusion process entirely on CPU on a server. I’d previously run an SD generator on my laptop without CUDA support, and while it was deathly slow it still worked. With this custom model, though, it took longer to initialise than I was prepared to wait — and I hate to think how long the subsequent image generation would have taken!3
I obviously needed something with a GPU, but I didn’t want to use my laptop as it may be unavailable or doing other more important things with its GPU like playing games. So I turned to AWS, and found they have GPU-enabled instances that can be obtained for reasonable amounts of money. As I didn’t really care when the batch processing ran, I could use “spot” instances which offer a decent discount in exchange for only being able to run when there aren’t reserved instances that need the resources.
After much fiddling in the AWS console, I got a spot reservation set up for a GPU-enabled instance. After waiting a while and not seeing any instances appear, I checked the logs and found it was erroring because I was trying to exceed my vCPU limit. Odd. A bit of googling4 later and I discover there’s a separate limit for that type of machine and the default limit is 0. There’s a whole mini application in AWS for requesting limit increases, so I requested a modest increase to 8 vCPUs (the minimum configuration for the “accelerated computing” images is 4 or 8 vCPUs depending on the exact type). After a brief wait, Amazon declined my request:
I am sorry but at this time we are unable to approve your service quota increase request.
Service quotas are put in place to help you gradually ramp up activity and decrease the likelihood of large bills due to sudden, unexpected spikes.
I’m not entirely sure how you’re meant to ramp up without being able to run a single instance. There are lots of theories online about account age requirements, minimum spends, etc, but I wasn’t willing to jump through inscrutable hoops in order to try to give Jeff Bezos more money. Instead, I looked at Paperspace, a service I’d come across previously when trying to run a GPU-enabled Windows box. They have a variety of GPUs on offer, and a lovely API to remotely manage machines. [If you want to try Paperspace you can use this referral link to get $10 off. In doing so you’ll give me enough credit to generate around 10,000 avatars. If that’s not a worthy cause, I don’t know what is.]
I went a bit overboard investigating the different GPU offerings and their relative bang for the buck:
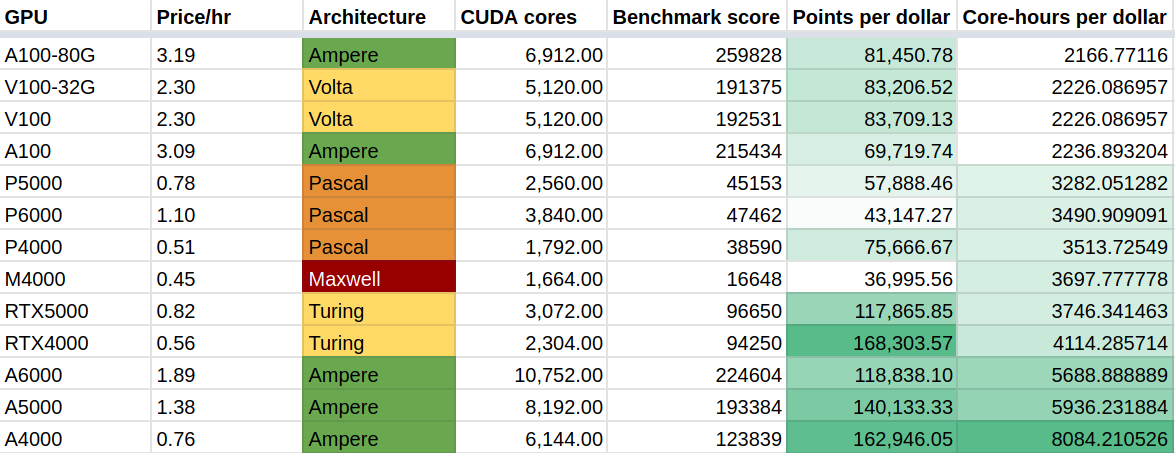
A slightly over-the-top analysis of the GPUs offered by paperspace
The A4000 comes out on top: it’s built on a modern architecture with a large number of CUDA cores, and is really competitively priced. Paperspace only give you access to the M4000 and P4000 initially and make you request access to the higher tier units. I dutifully filled out the very brief form, and a day later it was approved. At least someone is willing to accept my money!
Writing some code
After setting up the machine on Paperspace and copying over my custom model, I set about writing code to handle the generating and the serving. I eventually settled on having two buckets of images: ones that will be shown to only one person and deleted on use, and a fallback bucket that will be used multiple times. The fallback bucket is so that I can limit how many avatars I need to generate (and thus how much money I pay for GPU time5). I set a global limit of one avatar used every 10 minutes, as well as a per-IP limit of one unique avatar per 24 hours.
In order to distinguish whether you’re seeing a unique avatar, the server adds a border around it and a “UNIQUE LIMITED EDITION” label at the bottom. If you see that text, you’re looking at an image that has never been seen before and that has already been deleted. The server sends some aggressive caching headers, so in normal day-to-day operations you should see a different unique avatar every day you visit the site.
The generating side is a bit more interesting. It monitors the contents of the two avatar buckets, and springs into action if they fall below a configured minimum. It starts the process by calling Paperspace and requesting the machine is started up, then repeatedly polls the status endpoint until it’s ready. It then generates images individually using the REST API until it hits the bucket’s configured maximum. Once it’s done, it asks Paperspace to shut the machine back down.
Initially I just hardcoded a set of prompts for the generator to use, but they resulted in a lot of fairly similar images. To make things more interesting, I started dynamically generating the prompt using a combination of:
- A prefix such as “A painting of”, “A sketch of”, “A photograph of”
- In 80% of prompts, an artist reference such as “in the style of Andy Warhol”
- In 30% of prompts, a film reference such as “from the film The Matrix”
- 1-10 random suffixes such as “bokeh”, “8K”, “trending in Artstation”6
Initially I had the film and artist prompts independent, but the occasions where neither appeared in the prompt lead to pretty bad images. Instead, there’s now a 20% chance of a film reference, a 70% chance of an artist reference, and a 10% chance of both7. There’s a list of around 10 prefixes, 70 artists, 20 films and 20 suffixes which gives a large pool of random prompts.
End results
Everything I’ve described is now live on chameth.com – if you visit you might get a unique, never-been-seen before version of me. The code for the generating and serving is available on GitHub if you’re interested or want to replicate this for yourself.
To finish off, I ran off a batch of 200 avatars and have selected the most interesting ones:
A selection of avatars produced by the generator
As you can see there was one output that appears to be a cat with a ball of yarn, rather than a picture of me. That seems to happen occasionally when the various parts of the prompt don’t gel well, but I’m happy with 0.5% or so of the images being somewhat random! The batch of 200 avatars took just shy of 17 minutes to generate, which will result in a bill of $0.22 from Paperspace.
-
The famous quote from Arthur C Clark comes to mind when I think too much about how this works: “Any sufficiently advanced technology is indistinguishable from magic”. ↩︎
-
The only thing it doesn’t help with is finding enough pictures of yourself to use for the training data. That’s presumably easier if you’re more of a “selfie person” than I am. ↩︎
-
There were a lot of differences that could account for the extra slowness: my custom model was based on the larger 2.1 SD model rather than 1.5; I was using different software; and my laptop CPU is far more modern than the server’s. ↩︎
-
In the genericised sense: I used Duck Duck Go. ↩︎
-
One of my biggest concerns here was to avoid putting a “make Chris pay money” button on the Internet. That felt like a bad idea. ↩︎
-
AKA the random detritus that gets appended to prompts to make images better in mysterious ways. The English pedant in me hates this nonsense, but the results when you spam rubbish modifiers are inarguably better than when using straight forward prose. ↩︎
-
Imagining the Venn Diagrams is left as an exercise for the reader. ↩︎
Related posts
Coming around on LLMs
For a long time I’ve been a sceptic of LLMs and how they’re being used and marketed. I tried ChatGPT when it first launched, and was totally underwhelmed. Don’t get me wrong: I find the technology damn impressive, but I just couldn’t see any use for it. Recently I’ve seen more and more comments along the lines of “people who criticise LLMs haven’t used the...
Making a font of my handwriting
Recently I’ve been on a small campaign to try to make my personal website more… personal. Little ways to make it obvious it’s mine and personal, not just another piece of the boring corporate dystopia that is most of the web these days. I don’t quite want to fully regress to the Geocities era and fill the screen with animated under construction GIFs, but I do want to capture so...

Monthly Meanderings: January 2026
Welcome to the second edition of my monthly meanderings. For a bit of context, you can check out the introduction to the first edition. Website updates It’s been a pretty busy month for chameth.com. Three blog posts: The Meaning of Life — an entry into the IndieWeb carnival where I mostly review a book on Stoicism — Surge Protectors: Marketing vs Reality which is a dump of a rese...
{% figure "right" "A computer render of the author, with a \"UNIQUE LIMITED EDITION\" badge" %} I recently added a new 'about' section to the top of my website. Like most about pages, it has a pic...