Further Adventures in Music Organisation
Published on
I wrote before about how I’d dropped Spotify in favour of locally stored music, but things have advanced a bit since. I had a few issues: Tauon would occasionally manage to lose its database and along with it all my carefully constructed playlists and song ratings1, and the experience on my phone was not very fun.
I had to manually sync the music by plugging my phone in to the computer, and sometimes it just refused to mount the right partition. I don’t think there’s really a good way to debug an Apple phone not behaving properly when connected to a Linux desktop. Then I started wanting more than one playlist synced2, and trying to find a way to make that work just broke me.
I spent a while looking at different ways of hosting the music centrally. Plexamp gets lots of good reviews, and I’ve used Plex a fair bit. I set about spinning up a Plex server, and just could not get it working. The server ran fine, served the web interface, but would neither associate with my account nor run standalone. The docs were contradictory and there was very little useful logging. After a lot of frustration, I stumbled across mentions that Plex block running on Hetzner. I assume that’s the cause of my issues, although I have no way to know for sure. I use Hetzner for all my servers and other hosted services, but Plex have decided I can’t run the self-hosted software that I have a lifetime subscription for there. What the actual fuck?
I could have probably worked around the arbitrary restriction, but I didn’t want to throw more time down the drain. Instead, I set up Navidrome, an open source music server. It supports the Subsonic protocol, which means you can use a whole slew of different clients with it (or even write your own). It also means there’s a nice way to get data in and out of it programmatically, which I recall being a bit of a fight with Plex.
Syncing and organising
All my music lived on my desktop, but now I wanted it on my server. At first
I just used rsync to copy everything up. I’d maintain a local “master” copy,
and periodically shove the changes to the server3. That quickly got old,
so I set up Syncthing to keep the two folders in
sync. That worked… for a while.
Concurrently, I was looking at improving the organisation of my music. It was mostly organised by some Go programs I’d thrown together to automate the importing, with no real validation of metadata or anything else. Some albums got split up into multiple folders because the tracks had different artists (and didn’t have an album artist set); some artists ended up with multiple folders with slight spelling or case variations. It was upsetting.
I’d used MusicBrainz Picard before to fix some issues, but I didn’t really like the UI, especially when trying to do bulk actions. The main alternative is beets, which describes itself as “the music geek’s media organiser”, and is entirely command line. I was intrigued.
I started playing around with beets, and quickly noticed a problem. Every time I changed a metadata tag in a music file, Syncthing had to upload the entire file. I was frequently changing tags across the whole library as I got beets set up how I wanted, and Syncthing was handling it by uploading gigabytes of files for every minor change. I was already a bit unhappy with having the content duplicated in two places, so now I was using a command line organiser I figured I could just get rid of my local copy and move everything to the server.
I set up a Docker container for beets, and then wrote some incredibly hacky
shell scripts so I could run beet locally on my desktop and it would SSH
to the server over Tailscale and exec into the container, passing the arguments
along. Then I did one final sync of the music library, got rid of Syncthing,
double checked I had a backup and deleted all of my local music.
Bears, Beets, Battlestar Galactica
Beets is amazing. It has a vast array of plugins that can do almost anything you could want with a music library, and the command line workflow works really well for me. It’s very well documented, and all the individual parts are pleasingly simple and easy to understand.
Here’s what it looks like when importing some new music:
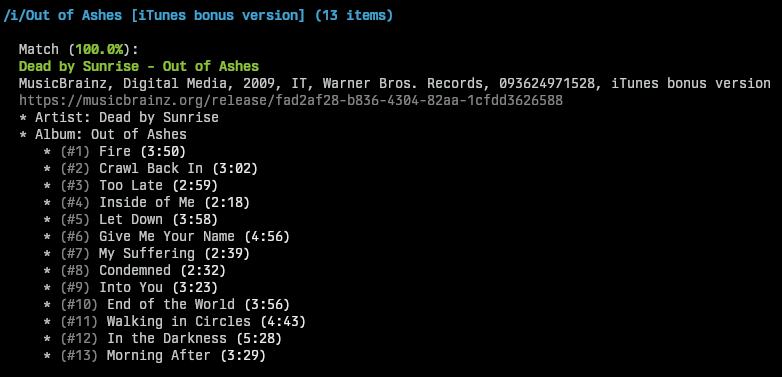
Beets importing an album
If it doesn’t get a perfect match then it shows the closest matches, and summarises what’s different about them (missing tracks, different names, etc), and lets you decide what to do. Aside from the metadata matching, it’s doing a lot of things under the hood that aren’t necessarily apparent. It:
- Looks up the genre from Last.fm
- Analyses all the tracks and writes ReplayGain metadata to them
- Fetches album art
- Checks all the files to make sure they’re actually playable
- Scrubs any existing metadata tags
It also maintains its own database, and you can query against it. The query language is both simple and quite powerful, like the rest of beets. As an example:
$ beet ls artist:"Linkin Park" year:2025 length:2:00..2:30
Linkin Park - From Zero - Casualty
Almost all the other commands also let you use the query syntax, which makes the whole tool really powerful. Want to delete all country tracks that you added last month? No problem. Redownload all the album art for a certain band? Easy. You can even do smart playlists using the filters.
Actually playing music
With all this organisation, I’ve not actually mentioned one tiny detail: how I actually play music now. Navidrome has a web UI, which is perfectly usable, but I don’t really want my web browser involved as it makes balancing sound levels tricky, and getting media keys working is a pain. Thankfully there are loads of Subsonic clients. I’ve tried several, but eventually settled on Feishin on the desktop. It’s very pretty:
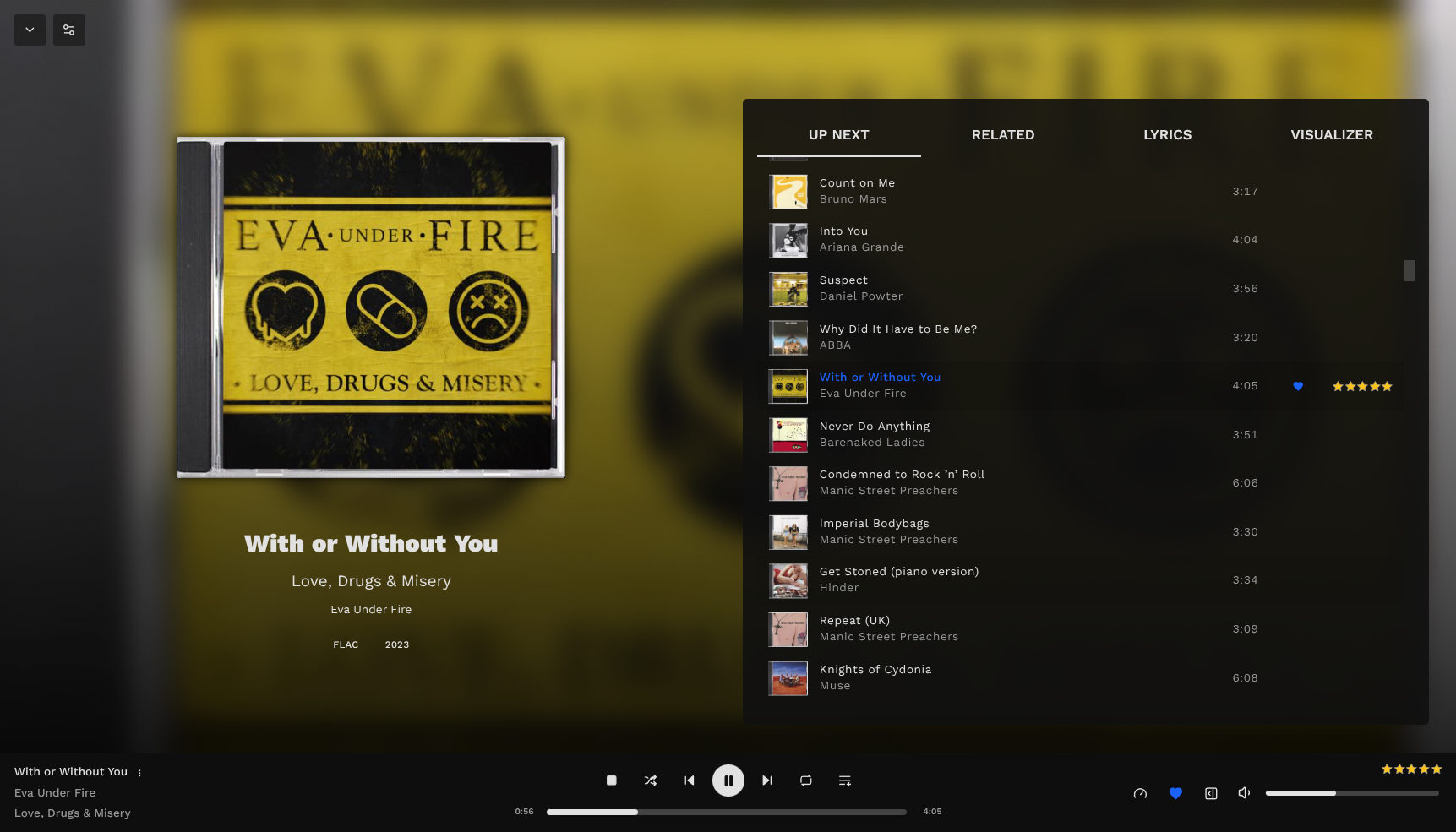
Feishin’s ’now playing’ screen
What attracted me to it, though, was its built-in support for Navidrome’s smart playlists. These aren’t even properly exposed in Navidrome’s web UI yet, but Feishin has a visual editor that lets you create and edit them. I ended up with an identical system to the playlists I had in Tauon: a “blacklist” playlist which are tracks I never want to play, a “favourites” playlist, and then an “everything” playlist which is the entire catalogue minus the blacklist.
On iOS I’ve settled on Arpeggi. It’s not actually on the App Store yet, but available via TestFlight. It’s one of those really nicely polished apps that are obviously a labour of love, not just out to do the minimum possible to get your money. It can cache songs offline, and automatically download entire playlists, and supports all of the standard Subsonic features like rating, reporting plays back to the server, and so on.
One unexpected benefit of using a central server is that it handles reporting plays to Last.fm and ListenBrainz instead of the clients. I don’t think I’ve ever bothered to configure my mobile clients to do that before, and now it just works automagically. I’m relying on those services more for recommendations and discovery, as that’s something you lose out on when self-hosting.
Making bad decisions about bitrates
With all the moving, copying, and organising, I started thinking about how large the collection was. The songs were all in different formats, depending on when and where I’d picked them up, and I couldn’t tell the difference between them. I did a test and transcoded an MP3 file down to 128kbps, and still couldn’t tell the difference. So armed with that sample size of 1, I transcoded the entire library and saved so much space.
I don’t remember which track I did that first test with, but it must have
been a very unlucky pick. I quickly started to notice the distortions caused
by the low bitrate. It was particularly bad in any song with a lot of treble,
and started to really annoy me. I started a painful process of reimporting
things in their original format. Beets came in clutch again, both with the
import process (if you import a duplicate album, it asks if you want to
replace the original, and shows the format and bitrate of them for comparison),
and keeping track of what was left to fix (beet ls bitrate:..128000).
Having started paying more attention to the sound quality, I think I’ve been nibbled on by the audiophile bug. I’ve been trying to get new music in FLAC format where possible. I’m pretty sure I can’t tell the difference between a decent bitrate MP3 and a FLAC, but maybe if I got a better DAC and some nice headphones…? Someone please hide my credit card!
As for the library taking up a lot of space, I now realise it’s a price worth paying. I might need to swap out the server to one with more storage at some point in the future, but it’s generally worth upgrading every few years with rented dedicated servers anyway, as you often get more for the same amount of money. Next upgrade I’ll just make sure there’s an appropriately-sized disk instead of focusing entirely on RAM and CPU.
Writing more code
Naturally, this whole process spawned several side projects. When browsing albums in Navidrome, I was a bit upset that the album art wasn’t all a consistent size. I thought about scripting something to crop them consistently, but then I had a better idea, and jewelcase was born. It takes the album art, crops it down to a consistent size, and then renders it inside a jewel case. It applies some slight effects, like adjusting the colours, rounding the corners, and tweaking the edges so it looks a bit more real. I don’t know why4, but every time I see the effect it gives me a little spark of joy.
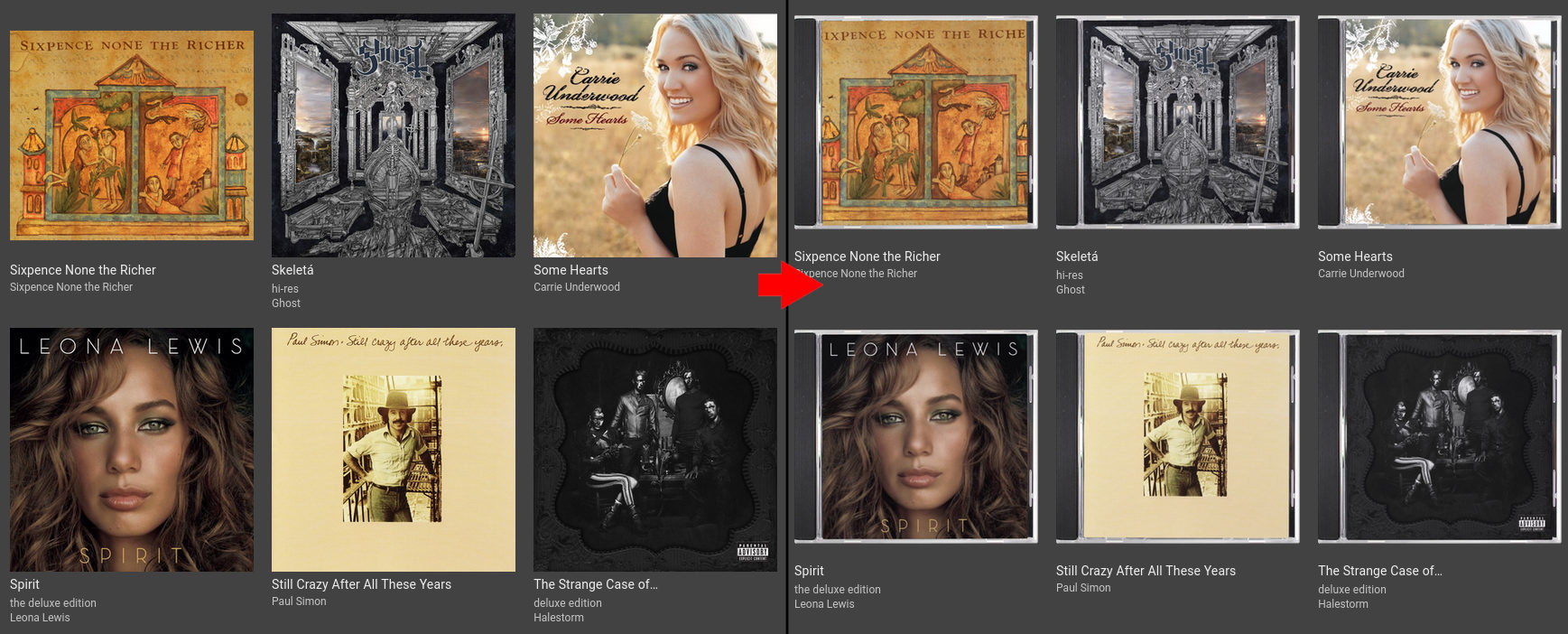
Album art, before and after jewelcase is applied
The other project is BASS, a tool that uses the Subsonic API to grab information about my music catalogue, and then generates a “Daily Mix” playlist. It uses a system of weights to select tracks semi-randomly, biasing towards favourite tracks, those that haven’t been played much, and a few other criteria. This gives me a nice balance between having my favourites on repeat, and exploring the full library at random.
All the weights in BASS are customisable, so I can tweak it to my heart’s desire, and anyone else can also run it and configure it entirely differently to me if they want to. I can’t imagine I would’ve been able to do that if I were using Plex!
-
I was running a version from git as the stable release had fun dependency issues on Arch, so it’s possible this wouldn’t be an issue in normal use. I also started backing up the database, but it’s still annoying to have to restore it. ↩︎
-
A “favourites” playlist for me, and a more “family friendly” playlist for when I’m playing music out loud that has a bit less screaming/swearing/etc. ↩︎
-
One of the reasons for starting this was being annoyed by the periodic sync to my phone, obviously it makes perfect sense to introduce a new, different periodic sync. ↩︎
-
Nostalgia? A little bit of OCD? Both? ↩︎
Related posts
Escaping Spotify the hard way
For the longest time I used Spotify for all my music needs. And I listen to a lot of music: sometimes actively, but mostly passively as background noise. I cancelled my premium subscription last December, and stopped using the service entirely. Why? There’s a bunch of reasons. Let’s talk about the money first. Spotify launched at £9.99/month, and stayed that way for over a decade. The...

Simple backups with Restic and Hetzner Cloud
I have a confession: for the past few years I’ve not been backing up any of my computers. Everyone knows that you should do backups, but actually getting around to doing it is another story. Don’t get me wrong: most of my important things are “backed up” by virtue of being committed to remote git repositories, or attached to e-mails, or re-obtainable from the original sourc...

Monthly Meanderings: February 2026
It doesn’t feel like a whole month has gone past since I wrote the last instalment of Monthly Meanderings, even allowing for how short a month February is. For more context on this series, you can check out the introduction to the first edition. Website updates I only wrote one new blog post this month: Just a nod, which is about the “nod” button I added to the bottom of most pag...
I wrote before about how I'd [dropped Spotify in favour of locally stored music](/escaping-spotify-the-hard-way/), but things have advanced a bit since. I had a few issues: Tauon would occasionally ma...